Sigma Lenses
We designed and implemented computer graphics algorithms using shaders to make magnification of high resolution data fast and independent of primary content rending.
Focus+context interaction techniques based on the metaphor of lenses provide in-place magnification of a region of the display, without requiring users to zoom into the representation and consequently lose context. To avoid occlusion of its immediate surroundings, the magnified region is often integrated in the context using smooth transitions based on spatial distortion. Such lenses have been developed for various types of representations using techniques often tightly coupled with the underlying graphics framework. We created a representation-independent, transparent approach to the implementation of lenses that applies to different graphics frameworks, ranging from 3D graphics to rich multi-scale 2D graphics combining text, bitmaps and vector graphics, while requiring minimal coding effort. This approach not only allows for the implementation of focus / context transitions based on spatial transitions, but also supports the full Sigma Lens model, which allows the definition of transitions between focus and context based on a combination of dynamic displacement and compositing functions. We implemented our general model in two very different frameworks: using OpenGL and programmable graphics hardware, and using a general-purpose cross-platform 2D application programming interface.
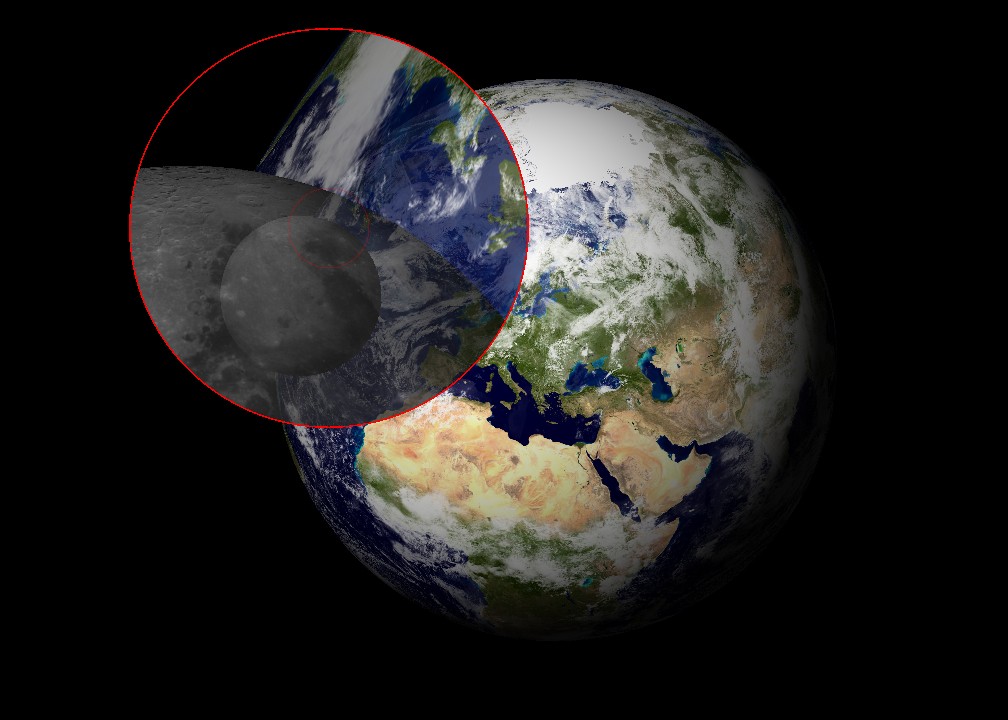
This speed-coupled blending lens is applied to a 3D model of the Moon orbiting the Earth. No modification of the scene is required. The lenses’ shape and behavior are defined independently in GLSL shaders.

Publications
Representation-Independent In-Place Magnification with Sigma Lenses.
E. Pietriga, O. Bau and C. Appert. 2009. In IEEE Transactions on Visualization and Computer Graphics.[IEEE]
Team and Credits
This work was conducted with Emmanuel Pietriga and Caroline Appert while at In|Situ| INRIA, Paris, France.
